Бит и байт
Содержание:
Биты
Интернет-площадка Getbeat – уникальный инструмент для творчества rap-музыкантов и исполнителей, где можно слушать рэп всех стилей и направлений, скачать биты лучших битмейкеров, разместить и продать свой собственный авторский минус. Сайт оборудован удобной системой поиска, которая поможет быстро найти все необходимые элементы мозаики для создания музыкальных шедевров:
- Биты
- Сэмплы
- Лупы
- Классическая минусовка и саундтреки популярных битмейкеров.
У нас вы найдёте качественный звуковой материал для широкодоступных программ, таких как MAGIX Music Maker, FL Studio, NanoStudio, а также для профессиональных платных приложений, например, Cubase, Ableton Live и Reason. Удобный и безопасный сервис по размещению и рекламе собственных произведений открывает широкие возможности не только для профессиональных создателей бит-композиций. Любой начинающий битмейкер сможет использовать наш ресурс как стартовую площадку и трамплин для творчества!
Бесплатные биты
Одним из преимуществ нашей творческой площадки является поддержка начинающих исполнителей и создателей музыки. Любой посетитель может скачать биты бесплатно, выбрав стиль и направление. У нас вы найдете тысячи треков в различных жанрах в свободном доступе. В каталоге представлены как бесплатные биты для рэпа без авторских прав, так и известные композиции, заслужившие мировую популярность и высокие рейтинги. Посетителям предлагается удобная поисковая система с возможностью качать понравившиеся треки:
- Коллекция постоянно обновляется, а все новинки можно быстро просмотреть, задав порядок выдачи (флажок «Сначала новые») в поиске.
- Можно быстро скачивать бесплатно готовые композиции для собственной текстовки.
- В нашей базе имеется достаточно образцов с хорошим инструменталом, которые будут полезны при создании новых битов.
Байт
С развитием компьютеров, появилась потребность в большем количестве значений для байта. В 1963-м году появилась первая редакция семибитной кодировки ASCII. Поэтому байты стали занимать 7 бит. 7 бит, требующиеся для одного символа данной кодировки позволяют использовать 128 значений. В этой кодировке уже были включены строчные латинские символы, и больший набор управляющих и арифметических символов.
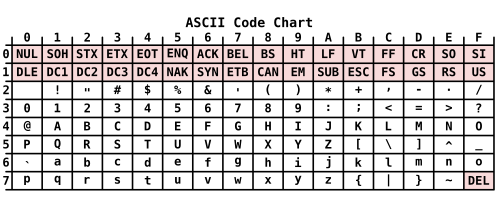
Всемирное распространение компьютеров подтолкнуло дальнейшее расширение границ занимаемых байтом. Для различных языков требовалось чтобы таблица символов также могла хранить алфавит того языка, где используется данная ЭВМ. На текущий момент восемь — это последнее и видимо окончательное количество бит составляющих байт. Соответственно байт может принимать 256 значений. По сравнению с таблицей ASCII в. новых таблицах символов — организовалось 128 вакантных мест. Теперь я думаю можно рассказать как значения хранятся в различных кириллических кодировках.
Чем отличается Кбит от Мбит?
В эпоху оптоволокна и накопителей объемом в десятки терабайт считать в битах не принято. Мы бы совсем забыли, чем отличается Кбит от Мбит, если бы не расхождения между обещаниями провайдеров и скоростью передачи данных в сетях, которая как раз и исчисляется преимущественно в этих единицах. Чтобы не растеряться при виде загадочных аббревиатур, надо знать:
- 1 бит – это не то же самое, что 1 байт (и даже с приставками кило- и мега-);
- в битах измеряют количество переданной информации, в байтах – объем хранимой;
- 1 байт (1 Б) = 8 бит (соответственно, 1 килобайт (Кб) = 8 килобит (Кбит) и т. д.).
Итак, и Кбит, и Мбит – это кратные биту единицы измерения количества информации, используемые сегодня преимущественно в контексте обсуждения скорости передачи данных в телекоммуникационных и компьютерных сетях.
Разница между Кбит и Мбит
Как известно на примере километров и мегабайтов, в СИ применяются десятичные приставки для обозначения умножения единиц на степени 10. Кило – 10³ (х 1000), мега – 10⁶ (х 1000000). Значит, основное отличие килобит от мегабит состоит в кратности биту:
1 Кбит = 1000 бит,
1 Мбит = 1000000 бит.
В то же время иногда килобитами и мегабитами называют и другие единицы – кибибиты (Кибит) и мебибиты (Мибит). Путаница возникла из-за принятия МЭК двоичной системы именования приставок, в которой единицы умножаются на степени 2. Получается, что
1 Кбит = 2¹º бит = 1024 бит,
1 Мбит = 2²º бит = 1048576 бит.
Вне зависимости от контекста измерения сразу видно, в чем разница между Кбит и Мбит: они соотносятся как меньшее к большему. Оперируют чаще двоичными битами, но иногда измеряют скорость и разрядность в двоичной системе, оставляя обозначение десятичным – так удобнее пользователям.
Количество состояний (кодов) в байте [ править | править код ]
Количество состояний (кодов, значений), которое может принимать 1 восьмибитный байт с позиционным кодированием, определяется в комбинаторике. Оно равно количеству размещений с повторениями и вычисляется по формуле:
N p = A ¯ ( n , k ) = A ¯ n k = n k = 2 8 = 256 <displaystyle N_
=<ar >(n,k)=<ar >_^=n^=2^<8>=256>возможных состояний (кодов, значений), где
N p
>— количество состояний (кодов, значений) в одном байте;
A ¯ ( n , k ) = A ¯ n k <displaystyle <ar >(n,k)=<ar >_^>— количество размещений с повторениями;
n <displaystyle n>— количество состояний (кодов, значений) в одном бите; в бите 2 состояния ( n = 2 );
k <displaystyle k>— количество битов в байте; в 8-битном байте k = 8 .
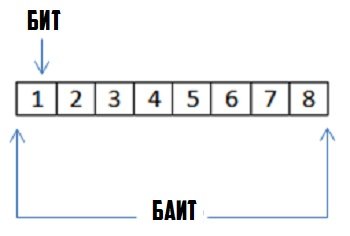
Сколько битов в Байте
Как Вы уже поняли выше, сам по себе, бит — это самая маленькая единица в системе измерения информации. Оттого и пользоваться ею совсем неудобно. В итоге, в 1956 году Владимир Бухгольц ввёл ещё одну единицу измерения — Байт, как пучок из 8 бит. Вот наглядный пример байта в двоичной системе:
00000001 10000000 11111111
Таким образом, вот эти 8 бит и есть Байт. Он представляет собой комбинацию из 8 цифр, каждая из которых может быть либо единицей, либо нулем. Всего получается 256 комбинаций. Вот как то так.
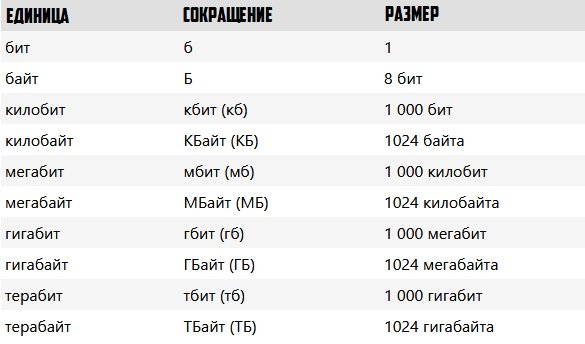
Килобайт, Мегабайт, Гигабайт
Со временем, объёмы информации росли, причём в последние годы в геометрической прогрессии. Поэтому, решено было использовать приставки метрической системы СИ: Кило, Мега, Гига, Тера и т.п.
Приставка «кило» означает 1000, приставка «мега» подразумевает миллион, «гига» — миллиард и т.д. При этом нельзя проводить аналогии между обычным килобитом и килобайтом. Дело в том, что килобайт — это отнюдь не тысяча байт, а 2 в 10-й степени, то есть 1024 байт.
Соответственно, мегабайт — это 1024 килобайт или 1048576 байт.
Гигабайт получается равен 1024 мегабайт или 1048576 килобайт или 1073741824 байт.
Для простоты можно использовать такую таблицу:
Для примера хочу привести вот такие цифры:
Стандартный лист А4 с печатным текстом занимает в средем около 100 килобайт
Обычная фотография на простой цифровой фотоаппарат — 5-8 мегабайт
Фотографии, сделанные на профессиональный фотоаппарат — 12-18 мегабайт
Музыкальный трек формата mp3 среднего качества на 5 минут — около 10 мегабайт.
Обычный фильм на 90 минут, сжатый в обычном качестве — 1,5-2 гигабайта
Тот же фильм в HD-качестве — от 20 до 40 гигабайт.
P.S.:
Теперь отвечу на вопросы, которые мне наиболее часто задают новички.
1. Сколько Килобит в Мегабите? Ответ — 1000 килобит (по системе СИ)
2. Сколько Килобайт в Мегабайте? Ответ — 1024 Килобайта
3. Сколько Килобит в Мегабайте? Ответ — 8192 килобита
4. Сколько Килобайт в Гигабайте? Ответ — 1 048 576 Килобайт.
Символ единицы
Символ единицы для байта определен в IEC 80000-13 , IEEE 1541 и Metric Interchange Format как символ верхнего регистра B.
В Международной системе количеств (ISQ) B — это символ бел , единицы логарифмического отношения мощности, названной в честь Александра Грэхема Белла , что противоречит спецификации IEC. Однако существует небольшая опасность путаницы, потому что ремень используется редко. Он используется в основном в десятичной дроби, децибелах (дБ), для измерения силы сигнала и уровня звукового давления , в то время как единицы для одной десятой байта, децибайта и других дробей используются только в производных единицах, таких как как скорости передачи.
Строчная буква o для октета определена как символ для октета в IEC 80000-13 и обычно используется в таких языках, как французский и румынский , а также сочетается с метрическими префиксами для кратных чисел , например ko и Mo.
Термин « октада» (е) для восьми битов больше не используется.
Зачем нам нужен порядок байтов
Несмотря на сатирическую трактовку Коэном борьбы «big endians» (прямого порядка, от старшего к младшему) против «little endians» (обратного порядка, от младшего к старшему), вопрос о порядке байтов на самом деле очень важен для нашей работы с данными.
Блок цифровой информации – это последовательность единиц и нулей. Эти единицы и нули начинаются с наименьшего значащего бита (least significant bit, LSb – обратите на строчную букву «b») и заканчиваются на наибольшем значащем бите (most significant bit, MSb).
Это кажется достаточно простым; рассмотрим следующий гипотетический сценарий.
32-разрядный процессор готов к сохранению данных и, следовательно, передает 32 бита данных в соответствующие 32 блока памяти. Этим 32 блокам памяти совместно назначается адрес, скажем 0x01. Шина данных в системе спроектирована таким образом, что нет возможности смешивать LSb с MSb, и все операции используют 32-битные данные, даже если соответствующие числа могут быть легко представлены в 16 или даже 8 битами. Когда процессору требуется получить доступ к сохраненным данным, он просто считывает 32 бита с адреса памяти 0x01. Эта система является надежной, и нет необходимости вводить понятие порядка байтов.
Возможно, вы заметили, что слово «байт» в описании этого гипотетического процессора нигде не упоминалось. Всё основано на 32-битных данных – зачем нужно делить эти данные на 8-битные части, если всё оборудование предназначено для обработки 32-битных данных? Вот здесь-то теория и реальность расходятся. Реальные цифровые системы, даже те, которые могут напрямую обрабатывать 32-битные или 64-битные данные, широко использую 8-битный сегмент данных, известный как байт.
В центре внимания:
1
- Название: Camp Foxx — VisaGangType Beat Ghetto
- Тональность: Соль минор — Gm
- Темп: 128 BPM
- Настроение: Мрачное, Грустное
- Жанр: Underground
- С припевом: Нет
- Лицензия
Camp Foxx — VisaGangType Beat Ghetto
00:00
00:00
2
- Название: lil Mill — Morphius
- Тональность: Ми-бемоль мажор — Eb
- Темп: 168 BPM
- Настроение: Расслабленное, Мрачное, Спокойное
- Жанр: Soul/Funk
- С припевом: Нет
- Лицензия
lil Mill — Morphius
00:00
00:00
3
- Название: Purpbeat — GOD level
- Тональность: Ре минор — Dm
- Темп: 145 BPM
- Настроение: Агрессивное, Расслабленное
- Жанр: Trap
- С припевом: Нет
- Лицензия
Purpbeat — GOD level
00:00
00:00
Онлайн калькулятор
Скорость передачи данных
Объём данных (размер файла) I = битбайткилобит (Kбит)кибибит (Кибит)килобайт (Кбайт)кибибайт (КиБ)мегабит (Мбит)мебибит (Мибит)мегабайт (Мбайт)мебибайт (МиБ)гигабит (Гбит)гибибит (Гибит)гигабайт (Гбайт)гибибайт (ГиБ)терабит (Тбит)тебибит (Тибит)терабайт (Тбайт)тебибайт (ТиБ)Время передачи данных t = секминчассуткигодСкорость передачи данных V =
бит в секунду (бит/с)байт в секунду (Б/с)килобит в секунду (Kбит/с)кибибит в секунду (Кибит/с)килобайт в секунду (Кбайт/с)кибибайт в секунду (КиБ/с)мегабит в секунду (Мбит/с)мебибит в секунду (Мибит/с)мегабайт в секунду (Мбайт/с)мебибайт в секунду (МиБ/с)гигабит в секунду (Гбит/с)гибибит в секунду (Гибит/с)гигабайт в секунду (Гбайт/с)гибибайт в секунду (ГиБ/с)терабит в секунду (Тбит/с)тебибит в секунду (Тибит/с)терабайт в секунду (Тбайт/с)тебибайт в секунду (ТиБ/с)Округление ответа: до целогодо десятыхдо сотыхдо тысячныхдо 4 знаковдо 5 знаковдо 6 знаковдо 7 знаковдо 8 знаковдо 9 знаковдо 10 знаковбез округления*
Объём данных
Скорость передачи данных V = бит в секунду (бит/с)байт в секунду (Б/с)килобит в секунду (Kбит/с)кибибит в секунду (Кибит/с)килобайт в секунду (Кбайт/с)кибибайт в секунду (КиБ/с)мегабит в секунду (Мбит/с)мебибит в секунду (Мибит/с)мегабайт в секунду (Мбайт/с)мебибайт в секунду (МиБ/с)гигабит в секунду (Гбит/с)гибибит в секунду (Гибит/с)гигабайт в секунду (Гбайт/с)гибибайт в секунду (ГиБ/с)терабит в секунду (Тбит/с)тебибит в секунду (Тибит/с)терабайт в секунду (Тбайт/с)тебибайт в секунду (ТиБ/с)Время передачи данных t = секминчассуткигодОбъём данных (размер файла) I =
битбайткилобит (Kбит)кибибит (Кибит)килобайт (Кбайт)кибибайт (КиБ)мегабит (Мбит)мебибит (Мибит)мегабайт (Мбайт)мебибайт (МиБ)гигабит (Гбит)гибибит (Гибит)гигабайт (Гбайт)гибибайт (ГиБ)терабит (Тбит)тебибит (Тибит)терабайт (Тбайт)тебибайт (ТиБ)Округление ответа: до целогодо десятыхдо сотыхдо тысячныхдо 4 знаковдо 5 знаковдо 6 знаковдо 7 знаковдо 8 знаковдо 9 знаковдо 10 знаковбез округления*
Время передачи данных
Объём данных (размер файла) I = битбайткилобит (Kбит)кибибит (Кибит)килобайт (Кбайт)кибибайт (КиБ)мегабит (Мбит)мебибит (Мибит)мегабайт (Мбайт)мебибайт (МиБ)гигабит (Гбит)гибибит (Гибит)гигабайт (Гбайт)гибибайт (ГиБ)терабит (Тбит)тебибит (Тибит)терабайт (Тбайт)тебибайт (ТиБ)Скорость передачи данных V = бит в секунду (бит/с)байт в секунду (Б/с)килобит в секунду (Kбит/с)кибибит в секунду (Кибит/с)килобайт в секунду (Кбайт/с)кибибайт в секунду (КиБ/с)мегабит в секунду (Мбит/с)мебибит в секунду (Мибит/с)мегабайт в секунду (Мбайт/с)мебибайт в секунду (МиБ/с)гигабит в секунду (Гбит/с)гибибит в секунду (Гибит/с)гигабайт в секунду (Гбайт/с)гибибайт в секунду (ГиБ/с)терабит в секунду (Тбит/с)тебибит в секунду (Тибит/с)терабайт в секунду (Тбайт/с)тебибайт в секунду (ТиБ/с)Время передачи данных t =
секминчассуткигодОкругление ответа: до целогодо десятыхдо сотыхдо тысячныхдо 4 знаковдо 5 знаковдо 6 знаковдо 7 знаковдо 8 знаковдо 9 знаковдо 10 знаковбез округления*
Кодировки
Итак, чтобы хранить символы не входящие в ASCII, необходимо было придумать новые кодировки. Поскольку до этого таблица ASCII была наиболее подходящей (были и другие), то она и пошла в основу новых кодировок. Поэтому следующие кодировки отличаются только значениями начиная с 80 (hex). Для наглядности оставлю только кириллические символы.
Так выглядела наиболее популярная кодировка под DOS. Примечательно что файлы в этой кодировке до сих пор встречаются. Как правило среди устаревшей архивной информации, в программах WinRar, Блокнот и WordPad, до сих пор есть опции «открыть как текст DOS», впрочем последними двумя мало кто пользуется =).
Кодировка koi8 была примечательна тем, что русские буквы там располагались на позициях английских звуков из нижней половины (т. е. ASCII). Это когда-то давно позволяло смягчить переход со старых серверов понимающие только ascii на новые, что было актуально среди почтовых серверов. Смысл был в том что если отправленное вами письмо приходило на старый сервер, то пользователю оно показывалось как транслит, что позволяло хоть как-то понять текст письма.
Самая популярная у нас в России однобайтная кодировка, на сегодняшний день, это именно «windows-1251». Разумеется популярность её целиком обусловлена популярностью Windows среди других операционных систем. Возможностей кодировки вполне хватает для использования её в широком круге задач. Например движок моего блога, по-умолчанию, использует для работы именно данную кодировку.
Я не могу не упомянуть о кодировке ISO, Удивительно, но несмотря на то что её никто никогда не использовал, эта кодировка является единственной кодировкой имеющей статус стандарта.
На примере данных кодировок видно, как один байт может хранить какое угодно символьное значение русского и английского языков, а также цифр и знаков пунктуации.
Но что делать когда этого не достаточно?
Многобайтные кодировки
Если вам хочется создать кодировку которая бы имела коды одновременно для русского и греческого алфавита? Одним байтом тут не отделаться. Появилась задача разработать кодировку один знак которой может занимать больше чем один байт, так как два байта могут принимать уже 2^16 = 65536 значений, а четыре байта аж 4294967296. Поэтому сначала придумали стандарт кодирования символов — Юникод, который включал бы в себя максимально полный перечень символов которые может принимать один знак.
Первая версия Юникода (Unicode 1991 г.) представляла собой 16-битную кодировку с фиксированной шириной символа; общее число разных символов было 216 (65 536).
Вторая версия Юникода (UCS-2), стала называться UTF-16, она позволяла гораздо расширить количество возможных значений, также используя для символов 16-битные последовательности (т. е. по 2 или по 4 байта на символ).
Кодировка UTF-32 (UCS-4) использует по 32 бита, или 4 байта на хранение одного символа. Строго говоря, стандарт Unicode не описывает символы со значениями выше 2^21, так что хватило бы и трёх байт, на символ, вероятно компьютеры работают несколько быстрее с мелкими блоками памяти кратными двум, или для того чтобы в сектор диска попадало кратное количество символов. Так или иначе это единственная из многобайтных кодировок с постоянной длиной. Помимо недостатка — использования четырёх байт на символ, у неё есть и очевидное преимущество — возможность прямой адресации к N-ному символу. В других кодировках требуется последовательное вычисление позиции каждого символа. Поэтому текстовые редакторы, внутри себя хранят всю информацию в виде UCS-4.
В 1992 году Кеном Томпсоном и Робом Пайком был изобретён формат UTF-8. Он отличается тем, что он ASCII совместим, и значения из таблицы Юникода могут занимать от 1 до 4х символов.
Символы UTF-8 получаются из Unicode следующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| — | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры | |
| — | кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит; сирийское письмо, тана, нко; МФА; некоторые знаки препинания | |
| — | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы | |
| — | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
Символы, в кодировке UTF-8, могут занимать до шести байт, но Unicode не определяет символов выше , поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
Байтовая адресация
Когда байты памяти печатаются последовательно слева направо (например, в шестнадцатеричном дампе ), младшее представление целых чисел имеет значение, увеличивающееся слева направо. Другими словами, при визуализации он появляется в обратном направлении, что может показаться нелогичным.
Такое поведение возникает, например, в FourCC или аналогичных методах, которые включают упаковку символов в целое число, так что оно становится последовательностью определенных символов в памяти. Давайте определим нотацию как просто результат записи символов в шестнадцатеричном коде ASCII и добавления их к началу , и аналогично для более коротких последовательностей ( в стиле Unix / MacOS):
' J o h n ' hex 4A 6F 68 6E ---------------- -> 0x4A6F686E
На машинах с прямым порядком байтов значение отображается слева направо, совпадая с правильным порядком строк для чтения результата:
| увеличение адресов → | |||||
| … | 4A ч | 6F h | 68 часов | 6E h | … |
| … | ‘J’ | ‘о’ | ‘час’ | ‘п’ | … |
Но на машине с прямым порядком байтов можно было бы увидеть:
| увеличение адресов → | |||||
| … | 6E h | 68 часов | 6F h | 4A ч | … |
| … | ‘п’ | ‘час’ | ‘о’ | ‘J’ | … |
Машины с прямым порядком байтов, такие как Honeywell 316 выше, еще больше усложняют это: 32-битное значение сохраняется в виде двух 16-битных слов ‘hn’ ‘Jo’ с прямым порядком байтов, которые сами имеют обратный порядок байтов (таким образом, ‘h’ ‘n’ ‘J’ ‘o’ ).
Этимология и история
Термин « байт» был придуман Вернером Бухгольцем в июне 1956 года на ранней стадии разработки компьютера IBM Stretch , который имел адресацию к командам битов и переменной длины поля (VFL) с размером байта, закодированным в инструкции. Это намеренное respelling от укуса , чтобы избежать случайной мутации к биту .
Другое происхождение байтов для групп битов, меньших размера слова компьютера, и в частности групп из четырех битов , зафиксировано Луисом Дж. Дули, который утверждал, что придумал этот термин во время работы с Жюлем Шварцем и Диком Билером над системой противовоздушной обороны. называлась SAGE в лаборатории Линкольна Массачусетского технологического института в 1956 или 1957 году и была разработана совместно Rand , MIT и IBM. Позже в языке Шварца JOVIAL фактически использовался этот термин, но автор смутно напомнил, что он произошел от AN / FSQ-31 .
Ранние компьютеры использовали различные четырехбитные двоично-десятичные представления (BCD) и шестибитные коды для печатных графических шаблонов, распространенных в армии США ( FIELDATA ) и военно-морском флоте . Эти представления включали буквенно-цифровые символы и специальные графические символы. Эти наборы были расширены в 1963 году до семи битов кодирования, названного Американским стандартным кодом для обмена информацией (ASCII) в качестве федерального стандарта обработки информации , который заменил несовместимые коды телетайпов, используемые различными ветвями правительства США и университетами в 1960-х годах. . ASCII включает различение букв верхнего и нижнего регистра и набор управляющих символов для облегчения передачи письменного языка, а также функций устройства печати, таких как перемещение страницы и перевод строки, а также физическое или логическое управление потоком данных во время передачи. СМИ. В начале 1960-х, будучи также активным в стандартизации ASCII, IBM одновременно представила в своей линейке продуктов System / 360 восьмибитовый расширенный двоично-десятичный код обмена (EBCDIC), расширение их шестибитного двоично-десятичного кода (BCDIC). ) представления, использованные в более ранних перфорациях карт. Известность System / 360 привела к повсеместному внедрению восьмибитного размера памяти, в то время как в деталях схемы кодирования EBCDIC и ASCII различаются.
В начале 1960-х годов AT&T представила цифровую телефонию на междугородних магистральных линиях . Они использовали восьмибитное кодирование по закону μ . Эти крупные вложения обещали снизить затраты на передачу восьмибитных данных.
Разработка восьмиразрядных микропроцессоров в 1970-х годах способствовала популяризации такого размера памяти. Микропроцессоры, такие как Intel 8008 , прямой предшественник и , использовавшиеся в ранних персональных компьютерах, также могли выполнять небольшое количество операций с четырехбитными парами в байте, например, десятичное добавление-регулировка ( DAA) инструкция. Некоторое количество четырех бит часто называют полубайт , также Nybble , который удобно представлен одной шестнадцатеричной цифрой.
Термин октет используется для однозначного определения размера в восемь бит. Он широко используется в определениях протоколов .
Исторически термин « октад» или « октад» также использовался для обозначения восьми битов, по крайней мере, в Западной Европе; однако это использование больше не является обычным явлением. Точное происхождение этого термина неясно, но его можно найти в британских, голландских и немецких источниках 1960-х и 1970-х годов, а также в документации по мэйнфреймам Philips .
Сети
Во многих документах IETF RFC используется термин сетевой порядок , означающий порядок передачи битов и байтов по сети в сетевых протоколах . Среди прочего, исторический RFC 1700 (также известный как Интернет-стандарт STD 2) определил сетевой порядок для протоколов в наборе Интернет-протоколов как , отсюда и использование термина «сетевой порядок байтов» для байтов с прямым порядком байтов. порядок.
Однако не все протоколы используют порядок байтов с прямым порядком байтов в качестве сетевого порядка. Протокол Server Message Block (SMB) использует порядок байтов с прямым порядком байтов. В CANopen многобайтовые параметры всегда отправляются первым младшим байтом (с прямым порядком байтов). То же самое и с Ethernet Powerlink .
В Беркли Sockets API определяет набор функций для преобразования 16-битные и 32-битных чисел и из сетевого порядка байт: (хост-сети короткие) и (хост-сеть длиной) преобразует 16- битовые и 32-битные значения соответственно от машины ( хоста ) к сетевому порядку; и функции преобразования из сети в порядке хоста. Эти функции могут быть не оп на большой обратный порядок байт системы.
В то время как сетевые протоколы высокого уровня обычно рассматривают байт (в основном обозначаемый как октет ) как свою атомарную единицу, сетевые протоколы самого низкого уровня могут иметь дело с упорядочением битов внутри байта.