Open source синтез речи sova
Содержание:
- Fromtexttospeech — онлайн сервис
- BookReader
- Как озвучить системное время в Windows и Linux
- ImgBurn 2.5.2.0 Portable [2010, Запись дисков]
- Интерфейс Балаболки
- Библиотека pyttsx3
- Acapela — сервис распознавания речи
- Преимущества и недостатки продукта от Google
- Как пользоваться синтезатором речи?
- Auslogics BoostSpeed Premium 7.2.0.0 RePack + Portable [2014, Оптимизация системы]
- Govorilka
- Модуль Google TTS — голоса из интернета
- Проблемы при работе с утилитой
- Лучшие речевые синтезаторы с русскими голосами
- Меняем Гугл Ассистент на Алису от Яндекс
- Ice Book Reader Professional
- Итоги
Fromtexttospeech — онлайн сервис
Чтобы перевести текст в речь онлайн можно также воспользоваться сервисом fromtexttospeech. Он работает по принципу конвертации текста в аудиофайл формата mp3, который затем можно скачать себе на компьютер. Сервис поддерживает конвертацию текста величиной в 50 тыс. символов, что является достаточно значительным объёмом.

Конвертирование текста в спич
- Для работы с сервисом fromtexttospeech перейдите на него, в опции «Select Language» выберите «Russian» (голос тут только один – Валентина).
- В большом окне введите (вставьте) нужный для озвучки текст, затем нажмите на кнопку «Create Audio File».
- Текст будет обработан, затем вы сможете послушать полученный результат, а потом и скачать его себе на ПК.
- Для этого нажмите правой клавишей мыши на «Download audio file» и выберите в появившемся меню «Сохранить объект как».
BookReader
Читай также: Как восстановить документ Ворд? Методы для всех версий

Book Reader
Приложение для чтения электронных книг.
Перерабатывает неупорядоченные тексты в безопасный для зрения, настраиваемый гипертекстовый формат.
Разрешает механизированную чёткую перекрутку информации, помнит положение чтения для каждой книги из локального хранилища.
Имеются функции:
- распределитель закладок
- механическое формирование наполнения книжки
- интегрированный веб-обозреватель онлайн библиотек.
BookReader механические загружает информацию с сайтов и перерабатывает в полновесные электронные книжки.
Эксплуатируются все стандартизованные кодировки народов мира и работа с ZIP, RAR, GZ архивами.
ПЛЮСЫ:
- механическая перекрутка информации
- распределитель закладок
- механическое формирование наполнения книжек
- интегрированный веб-обозреватель онлайн хранилищ
На сайт вернуться к меню вернуться к меню
Как озвучить системное время в Windows и Linux

Это крошечное приложение каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Создадим новый файл с именем time_tts.py. Всего, что мы разобрали выше, должно хватить, чтобы вы без проблем прочли и поняли следующий код:
# «Говорящие часы» — программа озвучивает системное время
from datetime import datetime, date, time
import pyttsx3, time
tts = pyttsx3.init()
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
tts.setProperty(‘rate’, 150) # Скорость в % (может быть > 100)
tts.setProperty(‘volume’, 0.8) # Громкость (значение от 0 до 1)
def set_voice(): # Найти и выбрать нужный голос по имени
voices = tts.getProperty(‘voices’)
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
else:
pass
def say_time(msg): # Функция, которая будет называть время в заданном формате
set_voice() # Настроить голос
tts.say(msg)
tts.runAndWait() # Воспроизвести очередь реплик и дождаться окончания речи
while True:
time_checker = datetime.now() # Получаем текущее время с помощью datetime
if time_checker.second == 0:
say_time(‘{h} {m}’.format(h=time_checker.hour, m=time_checker.minute))
time.sleep(55)
else:
pass
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+Break или Ctrl+C (в Windows и Linux соответственно).
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь оперативную память, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе и примеры. А пока посмотрим на другие инструменты.
ImgBurn 2.5.2.0 Portable [2010, Запись дисков]
Год выпуска: 2010Жанр: Запись дисковРазработчик: LIGHTNING UK!Сайт разработчика: http://www.imgburn.com/Язык интерфейса: Русский + АнглийскийПлатформа: Windows 2000, XP, XP x64, 2003, 2003 х64, Vista, Vista x64, 7, 7 x64Описание: ImgBurn — Отличная программа для записи дисков. Создана автором популярного, но закрытого в свое время проекта DVD Decrypter, предназначенного для копирования и снятия защиты с DVD дисков. Поддерживает запись на CD,DVD, HD DVD, BD и Blu-ray. С ее помощью можно выполнять запись из образов BIN, GCM, LST, UDI, CDI, FI, MDS, CDR, IMG, NRG, DVD, ISO, PDI), выбрать ин …
Интерфейс Балаболки
Balabolka имеет простой и интуитивно понятный интерфейс на русском и нескольких европейских и азиатских языках. Те, кто смог скачать Балаболку бесплатно, установил Balabolka и голосовой движок, чтобы программа смогла читать русскими голосами, сразу могут прослушать тексты. Процесс воспроизведения речи запускается кнопкой Воспроизведение. Кнопкой Пауза виртуальный рассказчик приостанавливается. Прекращается воспроизведение кнопкой Стоп. Такой же интерфейс управления присутствует в любом компьютерном аудио-видео плеере. Настроить программу для работы сможет даже малоопытный пользователь.
Возможность изменения дизайна программы на любой вкус реализована с помощью нескольких сменных скинов, или тем оформления интерфейса. Также существует возможность дополнительно бесплатно скачать темы для программы Балаболка с официального сайта. Мультиязычный интерфейс с превосходным русским языком и объемный раздел справки и помощи от автора программы Ильи Морозова вдвойне упрощает задачу изучения функционала, которого немного больше, чем может показаться на первый взгляд.
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
А теперь примеры!
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
import pyttsx3
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
voices = tts.getProperty(‘voices’)
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘=======’)
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
Результат будет примерно таким:
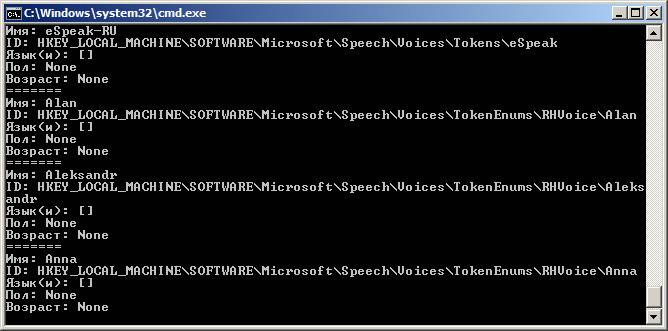
В Linux картина будет похожей, но с другими идентификаторами.
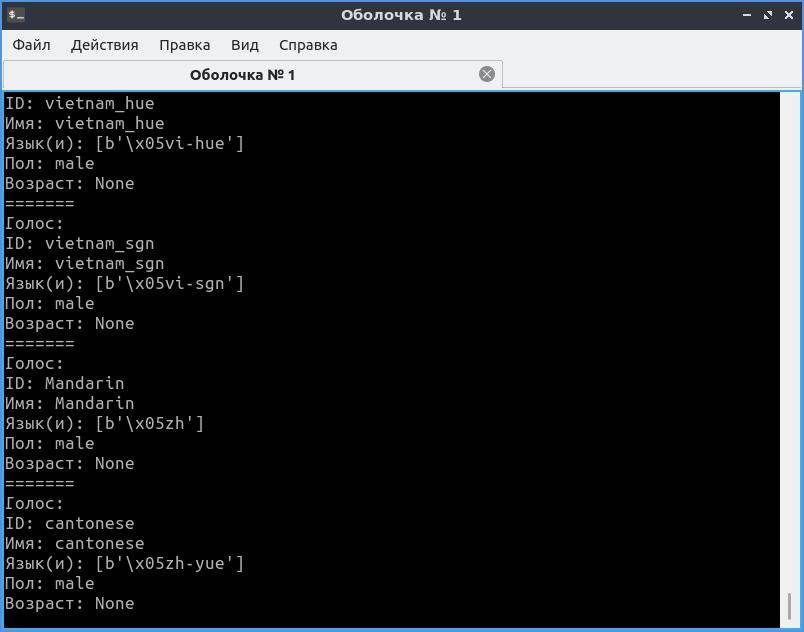
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
import pyttsx3
tts = pyttsx3.init()
voices = tts.getProperty(‘voices’)
# Задать голос по умолчанию
tts.setProperty(‘voice’, ‘ru’)
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
tts.runAndWait()
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait(). Выбор голоса по ID
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoice\Anna’) # Найти Анну от RHVoice
if ru > -1: # Eсли нашли, выбираем этот голос
tts.setProperty(‘voice’, voice.id)
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС
Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
import pyttsx3
tts = pyttsx3.init()
EN_VOICE_ID = «HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\MS-Anna-1033-20DSK»
RU_VOICE_ID = «HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\TokenEnums\RHVoice\Anna»
# Использовать английский голос
tts.setProperty(‘voice’, EN_VOICE_ID)
tts.say(«Can you hear me say it’s a lovely day?»)
# Теперь — русский
tts.setProperty(‘voice’, RU_VOICE_ID)
tts.say(«А напоследок я скажу»)
tts.runAndWait()
Acapela — сервис распознавания речи
Компания, торгующая своими голосовыми движками для различных технических решений, предлагает вам использовать синтезатор речи Acapela в режиме онлайн. Хотя просодия этого сервиса не на такой высоте, как у Ivona, тем не менее, качество произношения здесь тоже весьма добротное. Ресурс Acapela поддерживает около 100 голосов на 34 языках.

- Чтобы воспользоваться функционалом ресурса откройте указанный сервис, слева в окне выберите русский язык (Select a language – Russian).
- Вставьте внизу нужный текст и нажмите на кнопку «Listen» (слушать).
Максимальный размер текста для аудиопрочтения — 300 символов.
Преимущества и недостатки продукта от Google
Особенностями русскоговорящего женского голоса является четкое, громкое звучание и плавная интонация. Скорость воспроизведения можно регулировать в настройках программы
Пользователи, использующие TalkBack и русскую языковую локализацию ОС Android, должны проявлять осторожность при переключении на речевой синтезатор, если ранее в приложении по умолчанию был установлен другой голос. Могут возникнуть проблемы, связанные с сохранением контроля над мобильным устройством на слух
Практически все голоса, кроме русского, неспособны обрабатывать предложения на кириллице.
Среди минусов можно отметить задержку реакции на чтение текстов, состоящих из фраз на разных языках. Русский голос отличается металлическими нотками тембра. Можно услышать дребезжащий звук на низких частотах. К преимуществам можно отнести стабильность работы приложения и приемлемое качество чтения англоязычных слов.
Как пользоваться синтезатором речи?
Как правило, при первом запуске никаких настроек, кроме установки языка по умолчанию, производить не нужно. Правда, иногда программа может предложить выбрать качество звучания (в стандартном варианте, применяемом повсеместно, частота дискретизации 4410 Гц, глубина 16 бит и битрейт 128 кбит/с). В мобильных устройствах эти показатели ниже. Тем не менее за основу берется определенный голос. С использованием стандартного шаблона произношения путем применения фильтров и эквалайзеров достигается звучание именно такого тембра.
В использовании можно выбрать несколько вариантов перевода текста: ввод текста вручную, озвучивание уже имеющего текста из файла, интеграция в другие приложения (например, веб-браузеры) с активацией выдачи поисковых результатов или прочтения текстового содержимого на страницах онлайн. Достаточно выбрать нужный вариант действий, язык и голос, которым все это будет произноситься. Многие программы имеют несколько разновидностей голосов: как мужских, так и женских. Для активации процесса воспроизведения обычно используется кнопка старта.
Если говорить о том, как отключить синтезатор речи, тут может быть несколько вариантов. В самом простом случае используется кнопка остановки воспроизведения в самой программе. В случае интеграции в браузер деактивация производится в настройках расширений или полным удалением плагина. А вот с мобильными устройствами, несмотря на непосредственное отключение, могут быть проблемы, о которых будет сказано отдельно.
В музыкальных программах настройки и ввод текста намного сложнее. Например, в приложении FL Studio есть свой речевой модуль, в котором можно выбрать несколько типов голосов, изменить настройки тональности, скорости воспроизведения и т. д. Для постановки ударений перед слогом используется символ «_». Но и такой синтезатор годится только для создания роботизированных голосов.
Но вот пакет Vocaloid от Yamaha относится к программам профессионального типа. Технология Text-to-Speech здесь реализована в наиболее полном объеме. В настройках, помимо стандартных параметров, можно выставить артикуляцию, глиссандо, использовать библиотеки с вокалом профессиональных исполнителей, составлять слова и фразы, подгоняя их под ноты, и еще кучу всего. Неудивительно, что пакет только с одним вокалом занимает порядка 4 Гб и более в установочном дистрибутиве, а после распаковки. вдвое-втрое больше.
Auslogics BoostSpeed Premium 7.2.0.0 RePack + Portable [2014, Оптимизация системы]
Год выпуска: 2014Жанр: Оптимизация системыРазработчик: Auslogics Software Pty Ltd.Сайт разработчика: http://www.auslogics.com/ru/Язык интерфейса: Русский + АнглийскийТип сборки: RePack + PortableРазрядность: 32/64-bit Операционная система: Windows XP, Vista, 7, 8, 8.1 Описание: AusLogics BoostSpeed — приложение, которое поможет быстро и качественно произвести настройку ПК на максимальную производительность. Встроенный инструмент System Adviser проверит настройки системы с помощью пятидесяти различных тестов и предложит рекомендации по результатам каждого теста. Программа проверяет сист …
Программы / Системные приложения / Оптимизация, настройка и диагностика системы
Подробнее
Govorilka
Читай также: ТОП-10 сервисов для проверки текста на орфографию и пунктуацию

Goborilka
Компактный сервис для прочтения текста голосом. Он помогает прочитать вслух всякий текст на каком угодно языке и любым выбранным голосом.
Приложение напоминает сервис Balabolka.
Есть функция устранения пауз, эксплуатация внешних словарей и может взаимодействовать со ранними интерпретациями Windows.
Программа может функционировать с входящими объектами DOC и HTML, а трансформированные документы сохраняет с разрешением *.mp3 и *.wav.
Это приложение пригодится тому, кому в большей степени нравится прослушивать тексты, чем читать и кто беспокоится за здоровье своих глаз и хочет читать электронные книжки сидя вдали от процессора.
ПЛЮСЫ:
- присутствует функция удаления пауз
- взаимодействует со всеми версиями Windows
МИНУСЫ:
очень напоминает копию приложения Balabolka
На сайт вернуться к меню
Модуль Google TTS — голоса из интернета

Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS(‘Иван Федорович Крузенштерн. Человек и пароход!’, lang=’ru’)
tts.save(‘tts_output.mp3’)
После запуска этого кода в директории, где лежит скрипт, появится запись. Чтобы воспроизвести файл «не отходя от кассы», придется использовать еще какой-то модуль или фреймворк. Годится pygame или pyglet.
Вот листинг приложения, которое построчно читает txt-файлы с помощью связки gtts и PyGame. Я заметила, что для нормальной работы этого скрипта текст из text.txt должен быть в кодировке Windows-1251 (ANSI).
Проблемы при работе с утилитой
При необходимости пользователь может отключить приложение. В самых простых утилитах кнопка остановки находится в самой программе. Деактивация расширения, установленного в браузере, производится путем отключения дополнения или полного удаления плагина. При работе с программой на мобильном телефоне также могут возникнуть проблемы. Дело в том, что синтезатор речи автоматически включает загрузку ненужных пользователю языковых модулей.
Данный процесс занимает много времени и существенно расходует трафик. Как отключить «Синтезатор речи Google» на мобильном устройстве и избавиться от этой проблемы? Для начала нужно открыть настройки приложения. Потом необходимо выбрать раздел «язык и голосовой ввод». Далее нужно отметить последнюю строку.
Выбрав голосовой поиск, следует кликнуть по крестику у пункта «распознавание речи офлайн». Затем рекомендуется удалить кэш приложений. Далее требуется перезагрузить мобильный телефон. Чтобы полностью отключить утилиту, необходимо открыть в настройках раздел «приложения», выбрать в списке синтезатор речи и кликнуть по кнопке «остановить».
Лучшие речевые синтезаторы с русскими голосами
Программа RHVoice была создана Ольгой Яковлевой. Стандартный вариант приложения включает 3 голоса. Настройки очень просты. Программу можно использовать и как самостоятельное приложение, совместимое с SAPI5, и как дополнительный экранный модуль.
Речевой синтезатор Acapela отличается от аналогов идеальным озвучиванием текста. Приложение поддерживает более 30 языков мира. В бесплатной версии доступен лишь 1 женский голос.
Программа Vocalizer часто применяется в call-центрах. Пользователь может настроить постановку ударения, громкость и скорость чтения. При необходимости загружаются дополнительные словари. В приложении есть 1 женский голос. Речевой движок автоматически встраивается в программы для чтения книг в электронном формате.
Утилита eSpeak поддерживает свыше 50 языков. Недостатком программы можно считать сохранение звуковых файлов лишь в формате WAV, который требует много места на жестком диске.
Приложение Festival является мощнейшей утилитой синтеза речи, поддерживающей даже финский язык и хинди.
Меняем Гугл Ассистент на Алису от Яндекс
Алиса от Яндекс является аналогом ассистента от Google. Если вы хотите установить Алису по умолчанию, делаем следующее:
- Открываем Настройки >Приложения >Все приложения. Приложения > Все приложения. » width=»660″ height=»693″ srcset=»https://xiaominfo.ru/wp-content/uploads/2019/11/zameniaem-google-assistent-na-alisu-scr1.jpg 660w, https://xiaominfo.ru/wp-content/uploads/2019/11/zameniaem-google-assistent-na-alisu-scr1-286×300.jpg 286w, https://xiaominfo.ru/wp-content/uploads/2019/11/zameniaem-google-assistent-na-alisu-scr1-381×400.jpg 381w» sizes=»(max-width: 660px) 100vw, 660px» />
- Нажимаем на иконку в виде трех точек и выбираем Приложения по умолчанию.
- Далее находим пункт Помощник и голосовой ввод >Помощник. Помощник. » width=»660″ height=»696″ srcset=»https://xiaominfo.ru/wp-content/uploads/2019/11/zameniaem-google-assistent-na-alisu-scr3.jpg 660w, https://xiaominfo.ru/wp-content/uploads/2019/11/zameniaem-google-assistent-na-alisu-scr3-284×300.jpg 284w, https://xiaominfo.ru/wp-content/uploads/2019/11/zameniaem-google-assistent-na-alisu-scr3-379×400.jpg 379w» sizes=»(max-width: 660px) 100vw, 660px» />
- Далее выбираем «Яндекс» и готово.
Теперь вместо ассистента от Гугла вам будет помогать наша Алиса.
Синтезатор речи Google – предустановленное на многие устройства под управлением Android приложение, позволяющее озвучивать текст в других приложениях. Оно используется в приложениях для чтения книг, переводчиках, а также в TalkBack, которое озвучивает текст на экране, облегчая взаимодействие с устройством для людей с нарушением зрения.
В этой статье рассмотрим, как отключить синтезатор речи Google на Android телефоне или планшете.
Ice Book Reader Professional
Читай также: Как в Ворде перевернуть текст: Самые простые способы

Ice Book Reader
Обычная, но опциональная «читалка».
В приложении имеется много инструментов, которые сделают чтение электронных книг на дисплее с любой дистанции более комфортабельным.
Приложение даёт возможность выбрать индивидуальные параметры для скроллинга.
Главная особенность сервиса – интегрированная база данных и режим узнавания книг с неизвестной шифровкой.
Речевой синтез основывается на классическом движке и разрешает читать голосом заданный текст, если так хочет пользователь.
ПЛЮСЫ:
- есть опция скроллинга
- интегрированная база данных
- режим узнавания книг с неизвестной шифровкой
На сайт вернуться к меню
Итоги
Обычным пользователям и людям с ограниченными возможностями подойдут приложения с простым интерфейсом. Это может быть как RHVoice, так и «Синтезатор речи Google». Русский голос озвучит отображаемый на экране текст. Большего рядовому пользователю не требуется.
Музыкантам рекомендуется отдавать предпочтение профессиональной программе Vocaloid. В приложении есть дополнительные голосовые библиотеки и множество различных опций. Программа позволит получить естественное звучание голоса
Ведь музыкантам так важно, чтобы компьютерный синтез не ощущался на слух
Google открыла доступ к собственной технологии перевода печатного текста в аудио. С помощью Google Cloud Platform создатели приложений могут использовать синтез речи для внедрения функций автоответчика и озвучивания любого текста.
Разработчикам предлагается выбор из 32 голосов и 12 языков. В настройках можно изменять тембр, скорость и громкость. Поддерживаются разные форматы аудио, включая MP3 и WAV.
Улучшенный синтез речи
Технология основана на обновленной версии WaveNet, поэтому команда проекта уверена в правильном звучании даже сложного текста. Благодаря облачному процессору Google TPU, искусственная речь генерируется в 1000 раз быстрее: одна секунда воспроизведенного текста создается за 50 миллисекунд. Для более естественного звучания качество звуковых фрагментов повышено с 8 до 16 бит.
Для оценки качества речи были привлечены добровольцы. Созданные системой WaveNet аудиозаписи получили в среднем 4,1 балла. Для сравнения, голос реального человека был оценен максимум на 4,59 балла из 5:
Оценка качества обычного синтезатора, WaveNet и человеческой речи
Стоимость сервиса зависит от объема работы: стандартная система озвучивания стоит 4 $ за каждый миллион озвученных символов, а WaveNet — 16 $. Подробнее о технологии можно узнать в документации.
У системы перевода печатного текста в аудио от Google есть серьезные конкуренты. В феврале 2021 года технология Baidu Deep Voice научилась менять женский голос на мужской.
- https://trashbox.ru/link/google-text-to-speech-android
- https://androidlime.ru/google-speech-synthesizer-on-smartphone
- https://gemapps.ru/sravnenie/obzor-sintezatorov-rechi-dlya-android
- https://www.syl.ru/article/298926/chto-takoe-sintezatoryi-rechi-luchshie-sintezatoryi-rechi
- https://tproger.ru/news/google-text-to-speech-for-all/
ПОДЕЛИТЬСЯ Facebook
tweet
Предыдущая статьяSamsung Galaxy A5 2021 (SM-A520F) и его полные характеристики
Следующая статья